Lecture 1: Scope, Origins, and Methods in Psychology
ContentsExamples of Research in Psychology
Electrically Triggered Images & brain imaging
- Penfield and colleagues at the Montreal Neurological Institute in Montreal stimulated the brains of patients undergoing surgery who were under local anesthesia and therefore conscious. The patients reported seeing streaks and flashes, hearing clicks and buzzes, or produced involuntary movements, depending on the area of the brain being stimulated.
- Here we see a clear relation between physiological mechanisms and psychological phenomena.
- Recently, psychologists have started to use imaging techniques to examine the relation between blood flow in various regions of the brain and behaviour. (It is assumed that regions that are active will have increased blood flow.)
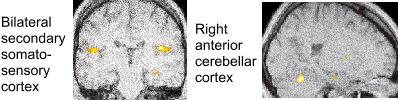
Example of an imaging experiment by Blakemore et al., (Nature Neuroscience, 1998) in which they used functional magnetic resonance imaging or fMRI to compare brain activity when a subject's hand was tickled by an experimenter or by themselves.
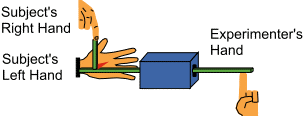
The yellow areas (below) showed reduced activation in self-generated tickling compared to tickling by the experimenter. Thus, the somatosensory cortex, involved in processing information from the skin, was less active when subject tickled themselves. These researchers suggested that in self-tickling, the cerebellum may act to cancel sensory inputs from the skin (before they reach the somatosensory cortex). The cerebellum is able to cancel the input during self-tickling because it can predict the pattern of sensory input. However, when the experimenter does the tickling, it is difficult to predict the pattern of sensory input.
- Many psychological phenomena are much further removed from issues that might be settled (or investigated) by biological investigations. To study these one proceeds at the psychological level alone.
- Consider the ambiguous vase. It can be viewed either as a vase or as two faces and is thus a reversible figure.

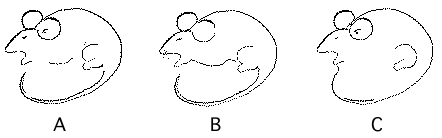
- It turns out that the way in which ambiguous figures such as the one above are perceived depends on what was seen just before. Consider the following ambiguous form shown in panel A below that can be seen either as a man or a rat. If you look at B and then A you will see a rat. However, if you look at C and then A, you will probably see a man. This is an example of perceptual bias.
- The same holds for language. Imagine you read the sentence shown below in the Kingston Whig Standard. If you had read an earlier article in the Whig about problem with excess drinking during frosh week, you would read the sentence one way. However, if the earlier article was about excess drinking among officers (perhaps because of frosh week!), you would read the sentence another way.
Perceptual World of Infants
- The phenomena we just considered stress the enormous effect of prior experience on what we see and do.
- However, not all psychological accomplishments are acquired by past experience.
- Gibson and Walk (1960) placed babies between 6 and 14 months of age on a "visual cliff" that consists of a board centered on a glass table top (see figure below). On one side of the board, a checkerboard pattern is attached directly to the underside of the glass; on the other side, the same pattern is placed on the floor three feet below. To adults, it looks like there is a sudden drop off in the center of the table. It appears that a six-month old infant see things in much the same way. Most of the infants would not crawl to their mothers when the mom was located on the "deep" side of the board.
- This indicates that the ability to perceive three-dimensional space comes at an early age. Note also that the infants do not crawl over the glass even though (hopefully) they have never fallen such a height before.

- Can we conclude that fear of heights is innate? No, because these babies are old!
- Campos and colleagues (Campos, Langer, & Krowitz, 1970; Campos & Langer, 1971) examined babies from 1 to 4 months. The researcher held the baby over either the deep or shallow side of the visual cliff and, as the baby were lowered toward the glass, measured their heart rate.
- The average heart rate when lowered over the deep side was 159 and the average rate when lowered over the shallow side was 168.
- Deceleration of heart rate usually is associated with interest. Acceleration of heart rate typically associated with fear.
- Thus, the researchers concluded that babies can discrminate the deep from the shallow side but they probably don't perceive danger.
- Thus far, we are considered individuals in isolation. However, much of the subject matter of psychology is concerned with social interaction.
- In animals, many social interactions depend on largely innate forms of communications. An example is courtship behaviour in birds - many species of birds have evolved elaborate rituals whereby one sex woos the others.
- Thus, the male peacock spreads his spectacular plumage and the red frigate inflates his red throat pouch. The males of other species offer gifts.

- In addition to courtship or mating displays, there are others displays such as threat displays and appeasement displays.
- Some inbuilt displays may form a foundation of emotional expression in humans - e.g., a baby smiling.
- Social interactions are generally more subtle and flexible in humans than they are in other animals.
- Much of human social life is based on one person's rational appraisal of how another person will respond to his/her actions.
- However, there are situations where humans act with little thought or reason. For example, under some circumstances, people in crowds behave differently than they do when alone.
Psychology is the Scientific Study of Behaviour and Mental Processes
Behaviour refers to the observable actions of an individual or animal. Observable (or measurable) actions include:
- Where the eyes are looking,
- How quickly a subject can press a key in response to a stimulus (reaction time),
- Answers to questions on a questionnaire,
- A subject's heart rate,
- The path that a laboratory rat takes when navigating a maze.
The following is a famous figure from Yarbus (1967). The subject looked at the photo on the left for a period of 3 minutes. The gaze position recorded during this period is shown on the right. The gaze record provides a crude repreesentation of the main contours of the phot. Note that most of the time, the subject looked at the eyes, mouth, and nose. These are the most visually informative regions.

Mental processes refer to an individual's perceptions, memories, thoughts, dreams, motives, emotions and other subjective experiences.
Thus, the psychology has two sides, one objective (behaviour) and the other subjective (mental processes). Psychologists measure behaviour and may use these measures to make inferences about mental processes. This means that when we speak scientifically about mental processes we have to be very clear what we mean.
Many researchers use operational definitions to define constructs such as memory or anxiety. An operational definition is based on a particular measurement.
Science is a approach to obtaining knowledge based on the scientific method.
Science deals with questions that can answered with observable facts. That is, it is concerned with testable hypotheses that deal with cause and effect. (Questions like "Why is the sky blue" are scientific questions. Questions like "is an orange a fruit" are not.)
• Click here for a RAPID FIRE history of Psychology!
Origins of PsychologyAlthough the first laboratory called a "Psychology Laboratory" was established only about 120 years ago, people have been interested in understanding psychological processes for a very long time. Indeed, the subject matter of psychology is as old as reflection. (If psychology is young, it is only young as a science.)
Modern psychology can be viewed as a synthesis of philosophy and physiology.

Philosophy
Historians trace the philosophical roots of psychology back to the ancient Greeks and philosophers such as Plato, Socrates, and Aristotle. The Greek philosophers were concerned with many fundamental psychological questions that inspire psychological research to this day.
They were interested in questions such as:
- Are People inherently good or evil?
- Do our perceptions equal reality?
- Do we have free will?
- How much do we know without learning?
They came up with an early theory of personality types and Aristotle also proposed laws of learning.
Philosophers have long been interested in two issues of particular relevance to psychology: the mind-body problem and nature versus nurture debate.
René Descartes (1596 - 1650)
Among other things, Descartes was interested in the mind-body problem which is concerned about the nature of the relationship between the workings of the body and mental phenomenon.
Descartes was a dualist, he believed that the "soul" or mind is a distinct entity from the body. He believed that a lot of human behaviour (even complex behaviour) involved just the body and could be viewed as reflexive responses to the environment.
He also believed that the reasoning (performed by the soul) had no physical basis. He thought that the soul received sensory information but then "thought" about this information through non-physical means.
Dualism may be contrasted with monism - the idea that thought and consciousness have a physical basis. Most psychologists today would not agree with dualism. It has serious limitations (for example, how can information be passed between physical and non-physical systems) and does not provide a very solid foundation for scientific psychology.
Thomas Hobbes (1588 - 1679)
Hobbes was a Materialist. According to the Materialists, concepts like spirit and the soul are meaningless. Everything, including consciousness, is the product of the physical machinery.
John Locke (1632-1704)
The English Philosopher John Locke was an Empiricist. He believed that, at birth, the mind is a tabula rasa (blank slate). The Empiricists thought that all knowledge derives from sensory experience. Knowledge is build up by forming associations between more elementary units.
Empriricism may be contrasted with theories that say we have some innate knowledge. (Recall that experiments with infants indicate that they have - or develop - depth perception at a very early age.)
The basic issue of nature versus nurture is alive and well in many fields of psychology today including language acquisition.
Physiology in the 19th Century
The science of physiology developed extremely rapidly in the 19th century (and at the end of the 18th century). A number of major events helped shape psychology.
Johannes Muller formulated his doctrine of specific nerve energies. According to this doctrine (1) the mind is directly aware not of objects in the physical world but of states of the nervous system and (2) the qualities of the sensory nerves are specific to the various senses.
Luigi Galvani electrically stimulates muscle and, in Britain, Bell and Sherrington and others began to make great strides in understanding the nervous system including reflex mechanisms in the spinal cord. Bell discovered the spinal cord contained two major pathways, one sensory (input) and the other motor (output). This work related behaviour and measurable neural activity and strengthened the concept that the two are intimately related.
Localization of Function in the Brain. Research with animals and people with head injuries was showing that specific damage leads to specific impairments in function. For example:
- Pierre Flourens performed lesion studies showing localization of function
- Fritsch & Hitzig electrically stimulated the brains of dogs and found a mapping between stimulation site and movement type
- Paul Broca described a patient with imparied speech who had focal brain damage in "Broca's area" (in the left hemisphere).
Darwin published Origin of Species published (1859) and other important works (e.g., Expression of Emotions in Man and Animals). His theories and observations convinced the intellectual world that humans are part of nature.
The Birth of Scientific Psychology
In Germany, the great physiologist and physicist Hermann Helmhotz (1821-1894) was studying the physiological mechanisms underlying sensation (e.g., colour vision) and action. One of the many things he was involved in was measuring the speed or rate of neural impulses and one of his research assistants was Wilhelm Wundt.
Wilhelm Wundt (1832 - 1920)
Wilhelm Wundt is often referred to as the founder of scientific psychology. In 1879, he open the first university-based psychology laboratory at the University of Leipzig in Germany. Wundt was particularly interested in the speed of simply mental process and carried out studies on simple and complex reaction time. He sought to identify elements of psychology and understand how they are combined.
In one experiment, he asked subjects to release a key as quickly as possible when a light came on and measured the delay between the light and the release (simple reaction time). In another experiment, subject held down two keys with the left and right hand. The subjects were instructed to release one key if the light was red and the other key if the light was green (complex reaction time). By subtracting the complex reaction time (290 milliseconds or ms) from the simple reaction (200 ms) Wundt determined the time required to categorize the colour and decide which key to release (90 ms).
Reaction time and stimulus-response compatibility. (An example of a more recent reaction time or RT study.)
Wallace's (J. Exp. Psych., Vol. 88, 1971) examined how quickly participants in his study could press one of two buttons in response to one of two lights flashing. He examined reaction times under four conditions:
- Compatible mappings between stimulus locations (*) and button locations and also between stimulus locations and effector (hand) locations.
- Incompatible mappings between stimulus locations (*) and button locations and also between stimulus locations and effector (hand) locations.
- Compatible mappings between stimulus locations (*) and button locations but incompatible mappings between stimulus locations and effector (hand) locations.
- Incompatible mappings between stimulus locations (*) and button locations but compatible mapping between stimulus locations and effector (hand) locations.
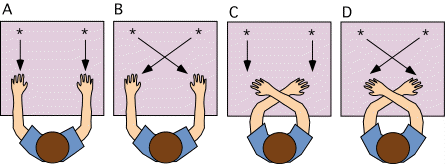
Wallace found that reaction times were faster in conditions A and C than in conditions B and D. (Note that this study examined choice reaction time as opposed to simple reaction time where there would only be one stimulus and one response.)
- The goal in sampling is to obtain a sample that is representative of the population of individuals or items that we are interested in studying.
- The way we ensure that the sample is representative is by choosing our sample using appropriate methods. The method of choosing a sample matters a lot!
- The best sampling methods involve the planned introduction of chance. (Random sampling is critical.)
- We need to watch out for a variety of biases when drawing a sample.
Problems with sampling
The LITERARY DIGEST Poll. (from Freedman et al., Statistics)
In 1936, Franklin Delano Roosevelt was completing his first year in office as president and it was an election year. The Republican candidate was Governor Alfred Landon of Kansas and the country was struggling to recover from the Great Depression. There were still 9 million unemployed and real income had dropped by one third in the period 1929 - 1933. Roosevelt wanted to spend money to help Americans (even if this meant running up the deficit) and Landon said that the spenders must go.
Most observers thought Roosevelt would win easily. However the Literary Digest predicted an overwhelming victory for Landon; with Roosevelt getting only 43% of the popular volt. This prediction was based on one of the largest number of people ever replying to a poll - about 2.4 million individuals! The poll was also backed by the enormous prestige of the Literary Digest which has called the winner in every presidential election since 1916.
However, Roosevelt won the 1936 election by a landslide getting 62% of the vote and the Digest's error was the largest ever made by a major poll. What went wrong?
The problem was certainly not due to sample size, which was plenty big enough. In fact George Gallup was able to predict the Digest prediction - well in advance of Digest publication using a sample of only 3,000 people. (He used the same lists as the digest and simply mailed people a postcard asking them how they would vote.) Using another sample of 50,000 people he correctly forecast the Roosevelt victory, although he was 6 % points off.
The main problem with the Digest poll was selection bias. The Digest mailed questionnaires to 10 million people. The names and addresses come from sources like telephone books and club membership lists. This tended to screen out the poor. At the time only one household in four had a telephone. Interestingly, data show that before 1936, rich and poor voted along similar lines. However, in 1936, the political split followed economic lines more closely.
Selection Bias. When a selection procedure is biased, taking a large sample does not help. It just repeats the basic mistake on a larger scale.
The Digest did a bad job in selecting their sample. However, they also did a bad job in getting the opinions of individuals in their sample. If a large number of those selected do not respond to the questionnaire or interview, what is known as non-response bias is likely. For example, in 1936 the Digest made a special survey in Chicago. Every third registered voter received a questionnaire. However, on about 20% responded. Of these, over 50% favoured Landon. However, in the election Chicago voted for Roosevelt by a 2 to 1 margin!
Non-Response Bias.Non-respondents can be very different from respondents. When there is a high non-response rate, look out for non-response bias.
Every effort should be made to cut down on non-response bias. For example, we know that more people response to a telephone interview than a questionnaire (especially individuals from the lower and upper classes). One can also offer rewards.
Other Biases
In a survey, respondents may lie or have a failure of memory or the way in which responses are solicited may be flawed (e.g., a leading question). Lying poses a particular problem - especially when the material is potentially embarrassing.
Response Bias. Response bias occurs when respondents give faulty information.
An Example: Two surveys are conducted to measure the effect of an advertising campaign for a certain brand of detergent. In the first survey, interviewers ask respondents whether they use that brand of detergent. In the second, the interviewers ask to see what detergent is being used. Would you expect the two surveys to give similar conclusions? Give your reasons.
ANSWER: We would not expect the results to be similar. For example, in the first survey, respondents may have been inclined to give the interviewer the answer they think s/he wants to hear. This would be an example of response bias.
Your textbook tells the story of "Clever Hans", the horse that could apparently answer all kinds of questions either by swaying his head or stamping out letters. However, The psychologist Oskar Pfungst showed that Hans could not answer any questions if he had blindfolds on or if he could not see a person who knew the answer! As it turned out, Hans detected whether the person was slightly moving his/her head and when the person looked down or up. This is a form of experimenter bias.
Experimenter bias. Experimenter bias can occurs when the experimenter (perhaps unwittingly) influences of the behaviour of participants or gives a biased interpretation of data.
A final word. Bad sampling can be costly. Shortly after 1936, the Literary Digest went bankrupt! On the other hand, Gallup is now very successful.
Controlled Experiments and Correlational Studies
Let us that say we want to examine the effects of mental practice on motor performance in University athletes. One way to do this would be to obtain a representative sample of students (who do not use mental practice) and assign each one to one of the groups: a mental practice group and a control group. Here the mental practice group is referred to as the treatment group. If the subjects in the experiment are randomly assigned to one group or the other we have a randomized control experiment. Of course, we would want to make sure that the person doing the evaluation of motor skill does not know which subjects were in the treatment group and which were in the control group. Another way would be to find 20 students who indicate that they use mental practice and compare these student with 20 others (matched on age, gender, etc.) who do not use mental practice. In both cases, the mental practice group would then be asked to do mental practice for some period of time and the other groups would be asked to continue on as before (i.e., not use mental practice.) At the end of the period, we would compare groups.
The first approach is a controlled experiment; the second is a correlation study (or observational study).
In a controlled experiment, the experimenter decides/controls who gets into which group. (If subjects are randomly assigned to one group or the other we have a randomized controlled experiment.)
In a correlation study, it is the subjects who "assign themselves" to one or the other group by virtue of their attributes prior to the study.
Controlled Experiments
Let us say that we want to test the effectiveness of a treatment. It could be a method of counseling, a new drug, or distorted visual feedback (e.g., a prism adaptation experiment).
The basic method is comparison. For example, a new drug is given to subjects in a treatment group, but other subjects, in a control group, they do not get the drug. The responses of the two groups are then compared.
In a good experiment, subjects should be randomly assigned to the treatment or control groups. Moreover, if possible and appropriate, the experiment should be run double-blind - neither the subjects nor the doctors who measure the responses should know who was in the treatment group and who was in the control group.
Key Points about Controlled Experiments
-
Statisticians use the method of comparison: they want to know the effect of a treatment on a response. To find out they compare responses of a treatment group with those of a control group.
-
If the control and treatment groups are similar, apart from the treatment, then a difference in the responses in the two groups is likely due to the treatment.
-
However, if the groups are different with respect to other factors, the effects of these factors are likely to be confounded with the effect of the treatment.
-
Experimentalists place subjects in the treatment and control groups at random in order to make sure that the treatment and control groups are alike.
-
Whenever possible, the control group is given a placebo - the response should measure the treatment and not the idea of the treatment.
-
In a double-blind experiment, neither the subjects nor those who evaluate the responses know whether a given subject is in the treatment of control group.
THE PORTACAVAL SHUNT
The importantance of randomized controlled experiments is illustrated by the following.
Cirriasis of the liver is a serious condtion which can even cause death. One way of treating this disease is to place a shunt into the liver to change blood flow. However, the surgury is long and hazardous. Do the benefits outweight the risks?
The following table summarizes the results of 51 studies on the Portacaval Shunt: 32 studies with patients but no controls, 15 studies with control patients but patients were not randomly assigned to either the control group or the treatment (shunt) group, and 4 studies in which patients were randomly assigned to one of the two groups. The table show the degree of enthusiasm that the investigators had for the shunt after the study.
|
51 studies on Portacaval Shunt |
|||
|---|---|---|---|
|
Degree of Enthusiasm
|
|||
|
Marked
|
Moderate
|
None
|
|
|
No Controls |
24 |
7 |
1 |
|
With controls but not randomaized |
10 |
3 |
2 |
|
With randomized controls |
0 |
1 |
3 |
In the studies without controls, 24 out of 32 studies (77%) found marked enthusiasm for the shunt. In the studies with controls but without random assignment, 10 out of 15 (67%) found marked enthusiasm for the shunt. However, in the studies with random assignment, none of the 4 studies found marked enthusiasm for the shunt. These results indicate that the investigators in the first two kinds of studies probably selected patients for the shunts that were likely to do well. This biases the findings. When this selection bias is removed by random assignment, we get a very different picture.
Correlational Studies and Confounding
Observational studies can be very powerful and in many cases are the only option for various reasons - including ethical reasons.Although randomized controlled experiments are the best, they are not always easy or even possible to do.
Medical research often used historical controls - a group of patient treated in the old way - to serve as controls for a new procedure. However, this is an observational studies and is therefore susceptible to the problem of confounding.
Confounding means a difference between the treatment and control groups - other than the treatment - which affects the responses being studied. A confounder is a third variable, associated with exposure and with disease.
Remember! Association is not Causation. Two variables may be associated but both may be affected by a third underlying and confounding variable. The following story illustrates the distinction between association and causation.
Ultrasound and low-birth weight
Human babies can now be examined in the womb using ultrasound. Several experiments on lab animals have shown that ultrasound examinations can cause low birthweight. If this is true for humans, there are grounds for concern. Investigators ran an observational study to find out, at the Johns Hopkins hospital in Baltimore.
Of course, babies exposed to ultrasound differed from unexposed babies in many ways other besides exposure; this was an observation study. The investigators found a number of confounding variables and adjusted for them. Even so, there was an association. Babies exposed to ultrasound in the womb had lower birthweight, on average, than babies who were not exposed. Is this evidence that ultrasound causes lower birthweight?
Discussion. Obstetricians suggest ultrasound examinations when something seems to be wrong. The investigators concluded that the ultrasound exams and low birthweight had a common cause - problem pregnancies. Later, a randomized controlled experiment was done to get more definite evidence. No harmful effects of ultrasound were observed. Association (between low-birth weight and ultrasound examination) is not the same as causation!
Source: Freedman, D., Pisani, R., and Purves, R., (1997). Statisitics, Third Edition. W. W. Norton & Company, New York, pp. 3-6.
EXTRA: The Clofibrate Trial
The Coronary Drug Project was a randomized, controlled double-blind experiment to test 5 drugs for the prevention of heart attacks. Subjects were middle aged men with heart trouble. Of 8,341 subjects, 5,552 were assigned at random to drug groups and 2,789 to the control group (placebo). The patients were followed for 5 years.
One of the drugs was Clofibrate. Unfortunately, this treatment did not save lives - about 20% of the the Clofibrate group died over the follow up period compared to 21% of the controls. A possible reason for failure was suggested - many patients in the Clofibrate group did not take their medicine.
Subjects who took more than 80% of the medicine (or placebo) were called adherers. For the Clofibrate group, the mortality rate among adherers was 15% compared to 25% among the non-adherers. Looks like strong evidence - but caution is in order. This particular observation is observational not experimental! Maybe the adherers were different than the non-adherers. In fact, the adherers in the control group also did better (15% mortality rate) than the non-adherers (28% mortality rate)
EXTRA: The Salk Vaccine Field Trial
The following material is included as another example of problems that can arise from biased samping and the advantages of controlled experiments.
Source: Freedman, D., Pisani, R., and Purves, R., (1997). Statisitics, Third Edition. W. W. Norton & Company, New York, pp. 3-6.
A new drug is introduced. How should an experiment be designed to test its effectiveness? The basic method is comparison.' The drug is given to subjects in a treatment group, but other subjects are used as controls-they aren't treated. Then the responses of the two groups are compared. Subjects should be assigned to treatment or control at random, and the experiment should be run double-blind: neither the subjects nor the doctors who measure the responses should know who was in the treatment group and who was in the control group. These ideas will be developed in the context of an actual field trial.
The first polio epidemic hit the United States in 1916, and during the next forty years polio claimed many hundreds of thousands of victims, especially children. By the 1950s, several vaccines against this disease had been discovered. The one developed by Jonas Salk seemed the most promising. In laboratory trials, it had proved safe and had caused the production of antibodies against polio. By 1954, the Public Health Service and the National Foundation for Infantile Paralysis (NFIP) were ready to try the vaccine in the real world-outside the laboratory.
Suppose the NFIP had just given the vaccine to large numbers of children. If the incidence of polio in 1954 dropped sharply from 1953, that would seem to prove the effectiveness of the vaccine. However, polio was an epidemic disease whose incidence varied from year to year. In 1952, there were about 60,000 cases; in 1953, there were only half as many. Low incidence in 1954 could have meant that the vaccine was effective or that 1954 was not an epidemic year.
The only way to find out whether the vaccine worked was to deliberately leave some children unvaccinated, and use them as controls. This raises a troublesome question of medical ethics, because withholding treatment seems cruel. However, even after extensive laboratory testing, it is often unclear whether the benefits of a new drug outweigh the risks. 3 Only a well-controlled experiment can settle this question.
In fact, the NFIP ran a controlled experiment to show the vaccine was effective. The subjects were children in the age groups most vulnerable to polio -- grades 1, 2, and 3. The field trial was carried out in selected school districts throughout the country, where the risk of polio was high. Two million children were involved, and half a million were vaccinated. A million were deliberately left unvaccinated, as controls; half a million refused vaccination.
This illustrates the method of comparison. Only the subjects in the treatment group were vaccinated; the controls did not get the vaccine. The responses of the two groups could then be compared to see if the treatment made any difference. In the Salk vaccine field trial, the treatment and control groups were of different sizes, but that did not matter. The investigators compared the rates at which children got polio in the two groups-cases per hundred thousand. Looking at rates instead of absolute numbers adjusts for the difference in the sizes of the groups.
Children could be vaccinated only with their parents' permission. So one possible design-which also seems to solve the ethical problem-was this: the children whose parents consent would go into the treatment group and get the vaccine; the other children would be the controls. However, it was known that higher-income parents would more likely consent to treatment than lower-income parents. This design is biased against the vaccine, because children of higher-income parents are more vulnerable to polio.
That may seem paradoxical at first, because most diseases fall more heavily on the poor. But polio is a disease of hygiene. Children who live in less hygienic surroundings tend to contract mild cases of polio early in childhood while still protected by antibodies from their mother. After being infected, they generate their own antibodies which protect them against more severe infection later. Children who live in more hygienic surroundings do not develop such antibodies.
Comparing volunteers to non-volunteers biases the experiment. The statistical lesson: the treatment and control groups should be as similar as possible -- except for the treatment. Then, any difference in response between the two groups is due to the treatment rather than something else. If the two groups differ with respect to some factor other than the treatment, the effect of this other factor might be confounded (mixed up) with the effect of treatment. Separating these effects can be difficult, and confounding is a major source of bias.
Using volunteers as subjects can lead to selection bias if the volunteers are different from non-volunteers.
For the Salk vaccine field trial, several designs were proposed. The NFIP had originally wanted to vaccinate all grade 2 children whose parents would consent, leaving the children in grades I and 3 as controls. And this design was used in many school districts. However, polio is a contagious disease, spreading through contact. So the incidence could have been higher in grade 2 than in grades 1 or 3. This would have biased the study against the vaccine. Or the incidence could have been lower in grade 2, biasing the study in favor of the vaccine. Furthermore, children in the treatment group, where parental consent was needed, were likely to have different family backgrounds from those in the control group, where parental consent was not required. With the NFIP design, the treatment group would include too many children from higher-income families. The treatment group would be more vulnerable to polio than the control group. Here was a definite bias against the vaccine.
Many public health experts saw these flaws in the NFIP design, and suggested a different design. The control group had to be chosen from the same population as the treatment group-children whose parents consented to vaccination. Otherwise, the effect of family background would be confounded with the effect of the vaccine. The next problem was assigning the children to treatment or control. Human judgment seems necessary, to make the control group like the treatment group on the relevant variables-fan-tily income as well as the children's general health, personality, and social habits.
Experience shows, however, that human judgment often results in substantial bias: it is better to rely on impersonal chance. For the Salk vaccine, the chance procedure was equivalent to tossing a coin for each child, with a 50-50 chance of assignment to the treatment group or the control group. Such a procedure is objective and impartial. The laws of chance guarantee that with enough subjects, the treatment group and the control group will resemble each other very closely with respect to all the important variables, whether or not these have been identified. When an impartial chance procedure is used to assign the subjects to treatment or control, the experiment is said to be randomized controlled.
When subjects are assigned to one or another group by chance, we refer to the process as random assignment. All experimenters should employ random assignment when possible.
Another basic precaution was the use of a placebo: children in the control group were given an injection of salt dissolved in water. During the experiment the subjects did not know whether they were in treatment or in control, so their response was to the vaccine, not the idea of treatment. It may seem unlikely that subjects could be protected from polio just by the strength of an idea. However, hospital patients suffering from severe post-operative pain have been given a "pain killer" which was made of a completely neutral substance: about one-third of the patients experienced prompt relief.
Still another precaution: diagnosticians had to decide whether the children contracted polio during the experiment. Many forms of polio are hard to diagnose, and in borderline cases the diagnosticians could have been affected by knowing whether the child was vaccinated. So the doctors were not told which group the child belonged to. This was double blinding: the subjects did not know whether they got the treatment or the placebo, and neither did those who evaluated the responses. This randomized controlled double-blind experiment-which is about the best design there is-was done in many school districts.
A double-blind experiment is when neither the subjects nor the individuals testing the subjects know which subject i sin which group. Double-blind experiments are the best.
How did it all turn out? Table 1 shows the rate of polio cases (per hundred thousand subjects) in the randomized controlled experiment, for the treatment group and the control group. The rate is much lower for the treatment group, decisive proof of the effectiveness of the Salk vaccine.
Table 1. The results of the Salk vaccine trial of 1954. Size of groups and rate of polio cases per 100,000 in each group. The numbers are rounded.
|
The randomized controlled |
The NFIP study |
||||
|
Group |
Size |
Rate |
Group |
Size |
Rate |
|
Treatment |
200,000 |
28 |
Grade 2 |
225,000 |
25 |
|
Control |
200,000 |
71 |
Grades 1 and 3 |
725,000 |
54 |
|
No consent |
350,000 |
46 |
Grade 2 |
125,000 |
44 |
|
Source: Thomas Francis, Jr., "An evaluation of the 1954 poliomyelitis vaccine trials-summary report," American Journal ofpublic Health vol. 45 (1955) pp. 1-63. |
|||||
Table 1 also shows how the NFIP study was biased against the vaccine. In the randomized controlled experiment, the vaccine cut the polio rate from 71 to 28 per hundred thousand; the reduction in the NFIP study, from 54 to 25 per hundred thousand, is quite a bit less. The main source of the bias was confounding. The NFIP treatment group included only children whose parents consented to vaccination. However, the control group also included children whose parents would not have consented. The control group was not comparable to the treatment group.
The randomized controlled double-blind design reduces bias to a minimum -- the main reason for using it whenever possible. But this design also has an important technical advantage. To see why, let us play devil's advocate and assume that the Salk vaccine had no effect. Then the difference between the polio rates for the treatment and control groups is just due to chance. How likely is that?
With the NFIP design, the results are affected by many factors that seem random: which families volunteer, which children are in grade 2, and so on. However, the investigators do not have enough information to figure the chances for the outcomes. They cannot figure the odds against a big difference in polio rates being due to accidental factors. With a randomized controlled experiment, on the other hand, chance enters in a planned and simple way-when the assignment is made to treatment or control.
The devil's-advocate hypothesis says that the vaccine has no effect. On this hypothesis, a few children are fated to contract polio; assignment to treatment or control has nothing to do with it. Each child has a 50-50 chance to be in treatment or control, just depending on the toss of a coin. Each polio case has a 50-50 chance to turn up in the treatment group or the control group.
Therefore, the number of polio cases in the two groups must be about the same. Any difference is due to the chance variability in coin tossing. Statisticians understand this kind of variability. They can figure the odds against a difference as large as the observed one. The calculation will be done in chapter 27, and the odds are astronomical-a billion to one against.