Lecture 6: Learning III and Review
Contents
Problems with Classical and Operant Conditioning as General Models of Learning
Cognitive View of Classical Conditioning
In general, the most effective type of classical conditioning is forward conditioning where the CS is presented ahead of the US (see figure below).

According to the traditional viewpoint, the CS gradually comes to be associated with the US during conditioning. Pavlov believed that the CS gradually becomes a substitute for the US so that the animal comes to respond to the CS just as it did to the US.
However, according to the cognitive perspective of classical conditioning, the CS does not become a substitute but , instead, becomes a signal that the CS will likely appear. In other words, what the animal acquires in classical conditioning is an understanding of the relation between the two stimulus events (i.e., the CS and the US).
According to the cognitive perspective, the relationship between the two stimuli is one of contingency rather than one of contiguity. Thus, in forward conditioning, the animal learns that the US is contingent on the CS - not merely that the two are associated in time in space (contiguous).
When the US is presented, there are other stimuli (e.g., the lights in the laboratory and smells in the laboratory) that are present. (Of course, the lights and smells are there through out the experiment but they are nevertheless contiguous with the US.) However, the animal does not learn to associate these stimuli with the US. Instead, they appear to understand that the CS predicts the likely presentation of the US. Thus, that conditioned response (CR) may be viewed as a preparation for the upcoming US (e.g., salivation in preparation for food).
Finally, whether the animal learns a contingency between the CS and the US will depend on the probability that the US will follow the CS. In general, animals will learn to respond (CR) to the CS only when there is a reasonably likelihood that the US will follow the CS.
Cognitive View of Instrumental Learning
Similarly, the cognitive view of instrumental learning holds that the animal acquires an internal representation of the relationship between the response (e.g., pressing a lever) and the reinforcer (e.g., delivery of juice). Thus, the animal learns to associate a particular act with its outcome, an association referred to as an act-outcome representation.
According to the cognitive view, in instrumental conditioning (as in classical conditioning), the animal learns the contingency between their actions and the outcomes produced. Support for this idea comes from an experiment by Watson (1967) - a different Watson than J.B. - in which infants were placed in cribs above which a colourful mobile was suspended. For one group of infants (left), the mobile would turn whenever the infants moved their heads (thus closing a switch). The infants in this group soon learned to shake their heads about, making their mobiles turn. They evidently enjoyed doing so and smiled and cooed at their mobiles. For the second group, the mobile turned just as often but was moved for them, not by them. After a few days, the infants in this group no longer smiled or cooed at their mobiles.

These results indicate that what the infants in the first group liked about the mobile was not that it moved but that they could control the movement. Clearly, infants can distinguish between response-controlled and response-independent outcomes - they can detect when a contingency is present or absent.
Important and early support for a cognitive view of instrumental learning was provided by work carried out by Tolman and colleagues in the 1920s, 30s, and 40's. One of their interests was in how rats learn to run mazes. At the time, many behaviourists thought that such learning consisted of a series of S-R bonds. However, Tolman rejected this view based on his experimental findings.
Edward C. Tolman (1886-1959)

Tolman trained rats to run a maze with alternate routes in order to obtain a reinforcer (food). After learning, the rats almost always chose the shortest route. However, when this route was blocked off, the rats immediately switch to the next shortest route and successfully obtained the reward. Tolman argued that this "insightful" behaviour and one-trial learning simply cannot be explained in terms of learned S-R (stimulus-response) habits. Clearly, the animals developed a cognitive map (an internal representation of the layout of the maze) during the initial learning and were able to consult this map to select the next best route following the blockade.
Tolman also showed that reward is not required for learning of the maze. He formed three groups of rats and placed them in a complex maze. For the first group, there was no reward; for the second, there was a reward on every trial (one trial per day); and for the third a reward was introduced only on the 11th trial (or day). On day 12, the third group of rats were almost as fast as the second group even though they had only received one reward trial! Tolman argued that reward affects what the animal does more than what the animal learns. He referred to this type of learning as latent learning (see Gray for details).
David Olten and colleagues have examined memory for locations using a radial maze. The following figure show the behaviour of a rat in a radial maze with food (purple rectangles) located at the end of each spoke. Initially, the rat goes down one spoke, eats the food (reinforcer), and then returns. Based on the principles of operant conditioning, we might expect the rat to then return to this location when they are hungry again. However, the rat chooses a different spoke. Indeed, rats can remember many such locations in a radial maze, rarely returning to a previously visited spoke.

Ecological/Evolutionary Perspective
Many of the results described above make sense from an ecological or evolutionary (adaptive) perspective of learning. For example, an ability to learn and make use of cognitive maps would surely be advantageous in terms of survival. Such ability would enable the animal to learn and recall the locations of food sources and predictors and determine appropriate routes between these locations.
An interesting example of learning that can best be understood from an evolutionary perspective is the foraging behaviour of the long-legged, fast-moving desert ant (Harkness & Maroudas, 1985). The following diagram illustrates the path of an ant who leave the nest, travels some distance, and then rather randomly searches for food. After finding the food - and taking a bite - the ant runs more or less straight back to its nest. This ability is impressive give that the hole to the nest is only 1 mm wide and the food may be as far as 50 metres away.
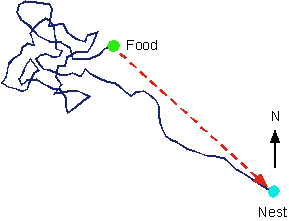
Careful experiments have shown that the ant uses movement velocity (speed and direction) integration to compute and update its current position. This information can then be used to compute the direction and distance back to the next. Thus, if the ant is displaced on its return journey, it will continue as if nothing had happened. In fact, it will run slightly past the nest and then start searching locally.
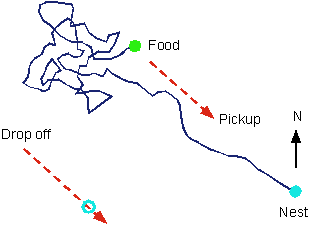
The process by which the ant returns directly to the nest involves a kind of learning. By interacting with the environment, the ant acquires information that is used to subsequently guide behaviour. Of course, this is a very different kind of learning than the kinds studied by Pavlov and Skinner. It involves in-built (inherited) mechanisms and immediate learning.
Extra details:
The ants nervous system must be able to preserve the value of a variable (position) over time and also be able to add new information to it. Path integration is a process the computes and stores values that specify a quantifiable objective fact about the world - the ant's direction and distance from its nest. Only when the ant decides to return, is this information used to guide bahaviour (the return run). Thus, the position-specifying values are not associative links between inputs and outputs. Rather they specify information used in a decision process (return home) that in turns specifies a behavioural output (return run). Interestingly, the ant also stores other key position information - for example, the location of a carcass - so that it can later return to it.
Ecological Validity - John Garcia and Food Aversion
Food aversion, a type of classical conditioning, does not require that the US (lithium) and CS (sheep) occur closely together in time. This is very different than the standard form of classical conditioning.
In standard classical conditioning, almost any stimulus can serve as the CS, but in food-aversion learning the stimulus must have a distinctive taste (or smell). Recall, that the wolf was not put off by the sight of the sheep, only the taste once it had the sheep in its mouth.
These responses are highly adaptive and illustrates how we must not forget about evolutionary factors when trying to understand learning mechanisms.
Insightful learning in Chimpanzees
Wolfgang Köhler observed learning in chimpanzees and concluded that learning was not gradual. Rather the chimps "wrestle" with the problem and then get answer right.
Wolfgang Köhler (1887-1968)

Köhler placed chimps in an enclosed play area and placed fruit out of reach.The chimps learned to use boxes and sticks to get the fruit. For example, chimps:
- used sticks as rakes to haul in fruit placed outside the cage,
- used sticks as pole to climb up and get fruit hung from above,
- and eventually even stacked boxes to get to fruit suspended from above.
Once solved, the task was performed smoothly - unlike Thorndike's cats. Köhler also observed transfer of learning. For example, if the boxes were replaced with tables after the chimp had learned to pile up the boxes, the chimp would immediately use the tables instead.

In class, I will give examples of exam questions and discuss how they might be answered.